|
Yifan Yin I am a second-year Ph.D. student in Computer Science at Johns Hopkins University, advised by Professor Tianmin Shu. Before my Ph.D., I completed my M.S.E. degree with a major in Robotics in the Laboratory for Computational Sensing and Robotics at Hopkins, under the supervision of Professor Russell Taylor and Professor Emad Boctor. |

|
ResearchMy research is at the intersection of embodied AI, 3D vision, robotics, and human-robot interaction. My recent work focuses on (1) 3D world modeling for anticipating and evaluating embodied state changes; (3) robot learning via multimodal reasoning and experience reflection; and (4) integrated task and motion planning for embodied assistance and human-robot collaboration. |
Publications |
|
|
3D-Belief: Embodied Belief Inference via Generative 3D World Modeling
Yifan Yin, Zehao Wen, Suyu Ye, Jieneng Chen, Zehan Zheng, Nanru Dai, Haojun Shi, Aydan Huang, Zheyuan Zhang, Alan Yuille, Jianwen Xie, Ayush Tewari, Tianmin Shu arXiv preprint, 2026 project page | arXiv | code | demo We propose world modeling as embodied belief inference in 3D space and introduce 3D-Belief, a generative 3D world model that maintains, samples, and updates explicit 3D beliefs from partial observations. |
|
|
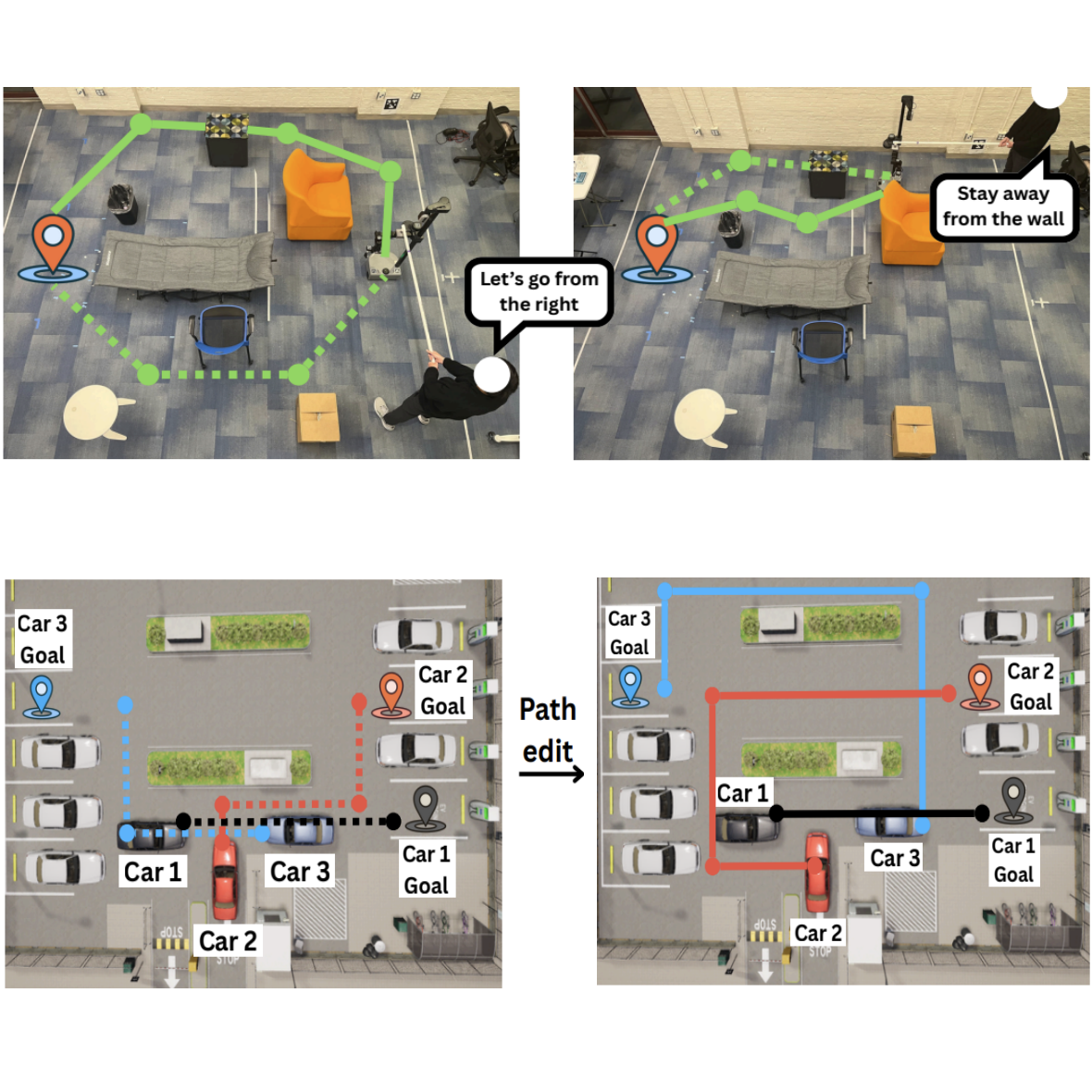
CaPE: Safe and Interpretable Multimodal Path Planning for Multi-Agent Cooperation
Haojun Shi*, Suyu Ye*, Katherine M. Guerrerio, Jianzhi Shen, Yifan Yin, Daniel Khashabi, Chien-Ming Huang, Tianmin Shu arXiv preprint, 2026 project page | arXiv We introduce CaPE (Code as Path Editor), which uses vision-language models to synthesize structured path-editing programs from natural language instructions, with a model-based verifier validating each edit for safe and interpretable multi-agent coordination. |


|
Fast Generative DeOcclusion for Visual Geometry and Robotics
Jieneng Chen*, Tiezheng Zhang*, Xiwei Xuan, Ju He, Yifan Yin, Haojun Shi, Suyu Ye, Xinyi Li, Ruisheng Yuan, Tianmin Shu, Alan Yuille Conference on Computer Vision and Pattern Recognition (CVPR) Findings, 2026 paper We present a fast geometry-aware generative framework for 3D de-occlusion, recovering hidden geometry and appearance to improve visual reconstruction, scene understanding, and robotic perception. |
|
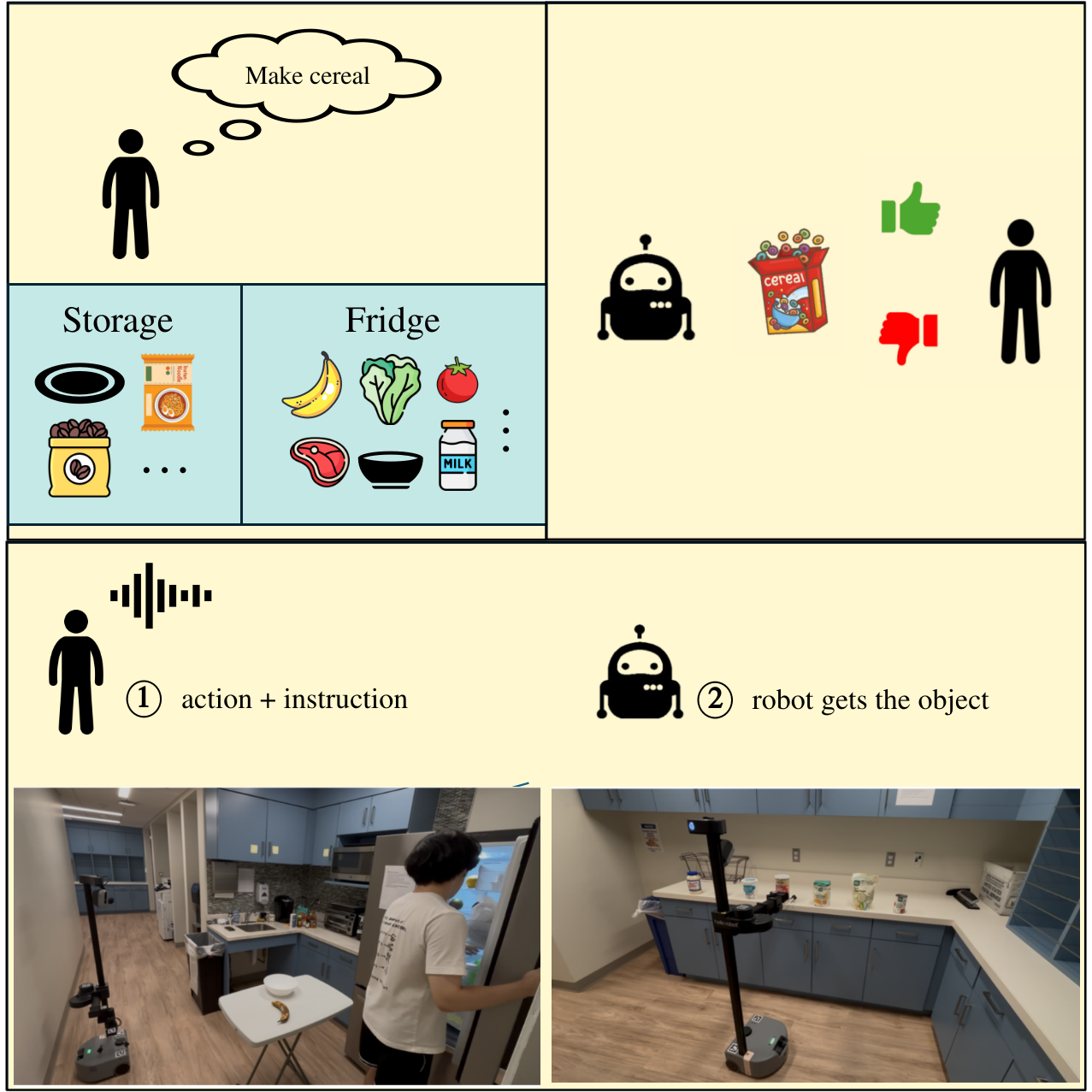
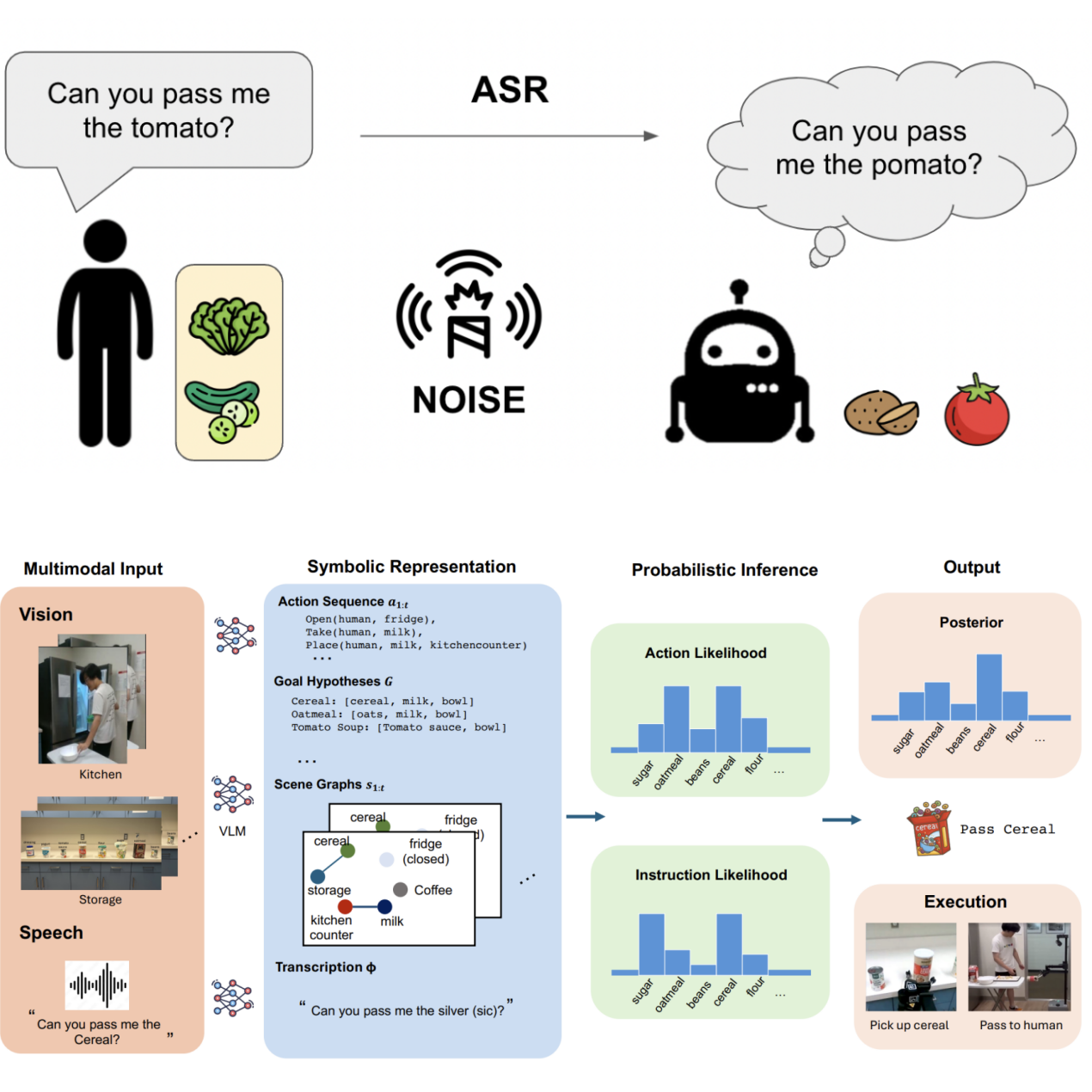
Pragmatic Embodied Spoken Instruction Following in Human-Robot Collaboration with Theory of Mind
Lance Ying, Xinyi Li, Shivam Aarya, Yizirui Fang, Yifan Yin, Jason Xinyu Liu, Stefanie Tellex, Joshua B. Tenenbaum, Tianmin Shu International Conference on Robotics & Automation (ICRA), 2026 arXiv We present SIFToM, a neurosymbolic model that uses vision-language theory of mind to help robots follow noisy spoken instructions in collaborative settings. |
|
Part-level Instruction Following for Fine-grained Robot Manipulation
Yifan Yin*, Zhengtao Han*, Shivam Aarya, Jianxin Wang, Shuhang Xu, Jiawei Peng, Angtian Wang, Alan Yuille, Tianmin Shu Robotics: Science and Systems (RSS), 2025 project page | arXiv | code We introduce PartInstruct, the first large-scale benchmark for training and evaluating fine-grained robot manipulation policies using part-level instructions. |
|


|
Applications of Uncalibrated Image Based Visual Servoing in Micro- and Macroscale Robotics
Yifan Yin, Yutai Wang, Yunpu Zhang, Russell H. Taylor, Balazs P. Vagvolgyi International Conference on Automation Science and Engineering (CASE), 2023 paper | arXiv We present a robust markerless image based visual servoing method that enables precision robot control without hand-eye and camera calibrations in 1, 3, and 5 degrees of freedom. |
Service
|
Media Coverage
|
|
Adapted from https://jonbarron.info/. |